What’s new with neural machine translation
Originally published at PangeaMT blog
I recently attended TAUS Tokyo Summit, where neural machine translation (NMT) was a hot topic. As Macduff Hughes from Google put it “Neural machine translation was a rumor in 2016. The first releases and tests happened six months ago and now it is here.” Although it is early days to make promises, the translation industry is clever enough not to overpromise once again. Having been in the eye of the storm at the times of “statistical machine translation fever”, I understand well enough the results are extremely promising, but no MT professional will tell where the technology is going to lead us. Since 2007, machine translation companies have built sophisticated platforms based on pure statistical machine translation for related language pairs, or hybrids (rule-based and SMT) when the language pairs involved had little to no grammatical relation. Controlling the input and making it more palatable and predictable to machine learning when grammatical structures were too different seemed the key to establishing statistical patterns. Morphologically rich languages always behaved better with rule-based technology. Statistics were applied to smooth out the final sentence.
What is an Artificial Neural Network?
In short, an Artificial Neural Network (or ANN for short) is a paradigm that processes information in a way that would make us think of our own biological nervous systems (with interconnected decision centers taking part and weighing on a decision). The key element of this (not new) paradigm is the structure of the information processing system, which in the case of humans is composed of a large number of highly interconnected processing elements we call neurons. Let us remember that not only humans are capable of making a decision. Many mammals can, as well, based on intuition, experience and “something” which has typically escaped us but we have called “a kind of intelligence”. Neurons work in unison to solve a specific problem. Artificial Neural Networks learn by examples, just like us. And to that end they need samples, i.e. data, massive amounts of data. A neural network can be configured to learn many things, not just bilingual patterns between two languages (two systems). It can also be used for any kind of pattern recognition (such as handwriting) or data classification (pictures, objects, shapes, etc.)
A neural network requires a learning process, after which it can create fairly accurate representations of queries. Taking the human (or mammal) example, a biological system requires adjustments to the synaptic connections that exist between the neurons – and this also happens in artificial networks.
Neural networks do not work miracles. But if used sensibly, they can produce some amazing results.
The beginning of a neural machine translation hype?
We may think it all started with Google’s post from their neural machine translation team. It seemed they finally had cracked the language barrier with outputs that were, surprisingly human.
The truth is that neural networks have been around in academia for the last 30 years (I would recommend an inspiring paper from 1997 by Castaño & Casacuberta from Jaume I University of Castellón and Universitat Politècnica de Valencia in Spain called “Machine translation using neural networks and finite-state models”). But even much earlier, back in the 1943, the first artificial neuron was produced by the logician Walter Pits the neurophysiologist Warren McCulloch. However, the technology available at that time did not allow them to do much. For many years, neural technology fell into disrepute and lack of funding. Research into statistical techniques and data processing have brought about a renewed interest in the neural, as well as the availability of GPUs. Neural networks are trained with the same type of graphic cards used by gamers and there is a simple and good reason for it: those cards are extremely efficient at carrying out mathematical calculations (for gaming it is the rendering of images). Neural networks are all about math. Whereas a CPU will have to look after general monitoring tasks such as controlling the hard disk, interfacing with the motherboard, controlling the temperature, accessing RAM, etc., GPU cards will do math and math only, whose results are quality graphics in the case of gaming, and quality output in the case of a neural network for machine translation.
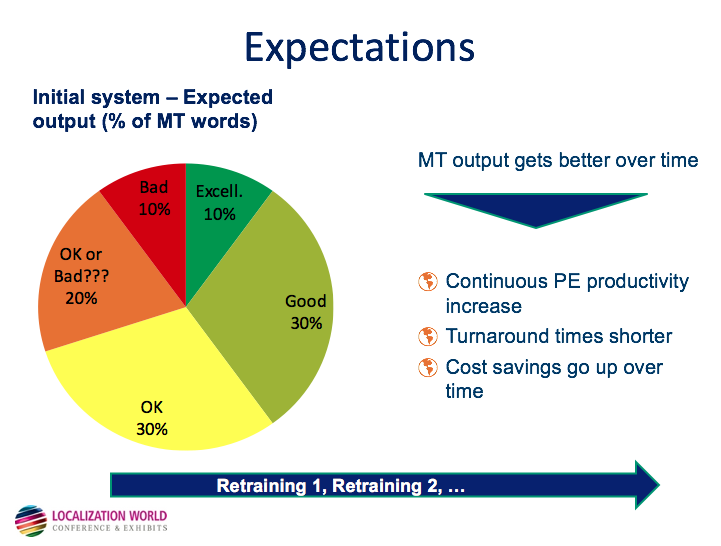
Google’s initial results –checked on line by an army of professional translators and aficionados- caused a flurry of conversation (and excitement) around the new neural machine translation’s ability to produce quality translations. The linguistic flare of the output was impressive and it has been followed by a surge in academic publications mentioning the “neural” and the recent announcement by Facebook that convolutional NMT can run 9 times faster and produce even better results. The new buzzword is neural networks, and the hype about artificial intelligence can only grow. The truth is we do not know until when and until where the new technology can take us. This graph from our presentation at LocWorld 2011 will easily illustrate our starting point. The presentation was a report from one of our clients, Sybase for an English-German SMT engine with a fairly low amount of data at the time, 5M words.

Although the training sets were different, both were related to software field. The point is how human evaluators ranked 10% as excellent and 30% as good in comparison to a 53% perfect or almost perfect and 39% “light post-editing” required. So that is a 40% very good or good enough in German compared to an impressive 92% with neural networks. The starting point is very, very promising, twice as high as with SMT.
NMT is still in its infancy. It makes unpredictable errors that are not easily spotted. There is no terminology management, so customization is much harder. It is, thus, unreliable. It is machine translation and natural language processing, let us not forget. A lot of the work that was done by the Moses community has to be done all over again (connectors to CAT tools and API services, to name just two). However, the hype is only natural because of the higher level of acceptability of machine translation in general and the higher quality of the results.
What’s PangeaMT doing with neural machine translation?
Today, PangeaMT has a very sophisticated and fully integrated machine translation solution that makes use of resources gathered from public repositories and think tank organizations such as TAUS and the European Union for most working language pairs. Our switch to neural machine translation means we need to adapt our previous platform to an all-new way of working, with brand new connectors, plug-ins and API architecture. Nevertheless, the above results are extremely promising, with human evaluation pointing to 80%-90% “human quality output” or “very good output with light post-editing required” in most language pairs. Pangeanic’s translation services look after the human quality aspect when machine translation is not used as a raw service but as a pre-publication service in order to aid linguists. Our translation automation specialists are constantly creating gathering new data, terminology, adding new language pairs, training and retraining machine translation engines in order to improve final output quality.
Since our machine translation technologies are fully integrated with ActivaTM and Cor technologies, (our revolutionary translation memory system that is not dependent on a CAT tool and our automated document and website quote and document translation and website translation ordering system), a large part of the translation workflow can be automated and enhanced, from order to payment, traceability, terminology management and document delivery.
PangeaMT employs a diligent machine translation onboarding process for clients considering the use or deployment of machine translation. Although certain criteria in terms of training data volume have to be met (number of previously translated bilingual segments, engine training and testing, customization and fine-tuning, choosing an onsite or API use, etc), our use cases provide the perfect setting for 21st century language automation.
Are you considering adopting neural machine translation? Feel free to comment and contact us!
About author:
Manuel Herranz is the CEO of Pangeanic and the developer of the PangeaMT system for translation companies. He worked as an engineer for Ford machine tool suppliers and Rolls Royce Industrial and Marine, handling training and documentation from the buyer’s side when translation memories had not appeared in the LSP landscape. After joining a Japanese group in the late 90’s, he became Pangeanic’s CEO in 2004 and began his machine translation project in 2008 creating the first, command-line versions of the first commercial application of Moses (Euromatrixplus). PangeaMT is now a full division that differentiates itself by not providing just engines but a whole MT system users can model to their needs